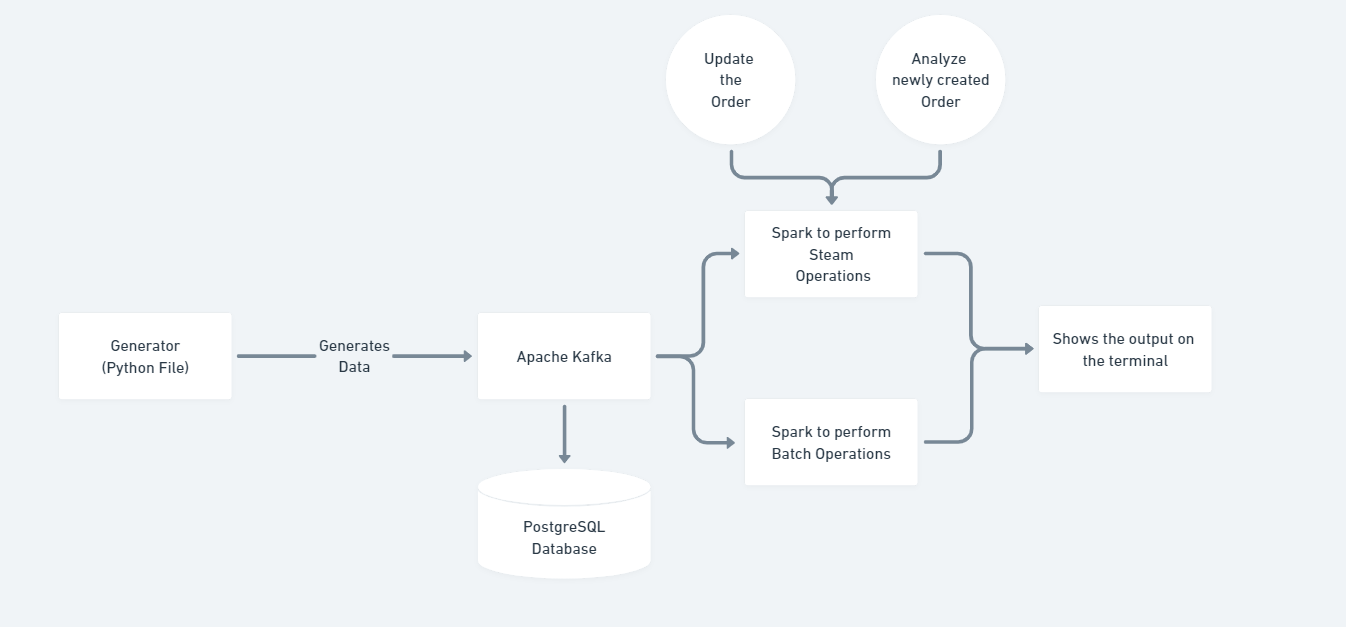
Here's a food-delivery analytics project, built using Kafka and Spark
- NEW_ORDER
- ORDER_UPDATE
- We wrote a python script, which generates new orders with each packet as:
{ 'orderId': '452b299d-0d58-4f0e-a3c5-e9c5c6175c3b', 'customerId': '5b39f4c2-83be-460b-85a2-5798483dc919', 'hotelId': 1, 'hotelName': 'Hotel 1', 'items':[{ 'category': 'Chinese', 'name': 'Fried Rice', 'price': 544, 'quantity': 2 }], 'netPrice': 544, 'discountPrice': 250.62, 'createdAt': '2023-04-28 12:29:54', 'payment': 'wallet' }
And order-update packets which are generated on sequential-order of status:
{'orderId': '452b299d-0d58-4f0e-a3c5-e9c5c6175c3b', 'status': 'order-cancelled', 'hotelId': 1, 'hotelName': 'Hotel 1', 'customerId': '5b39f4c2-83be-460b-85a2-5798483dc919' }
- We would publish in the respective topics using kafka
- The batchConsumer, listens to NEW_ORDER topic and writes the specific-item details to the database
- The two consumers: orderStreamConsumer and orderUpdateConsumers are described below and batchProcessor is described below
Operations:
- Top selling item in a window of 60secs
- Top selling category in a window of 60secs
- Maximum Order value in last 60 secs window.
- Number of total orders per day
- Max order value per day
- Most sold category per day
- Total Revenue in one Day
- Group-By number of order-status updates