{kind=link}
cloudcast is a U-Net based convolutional neural network for total cloud cover prediction. cloudcast is used operationally at FMI to provide short term cloud cover nowcasts.
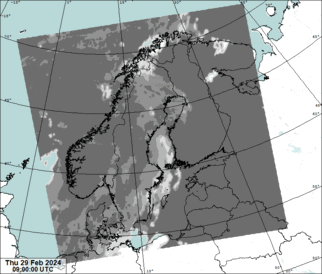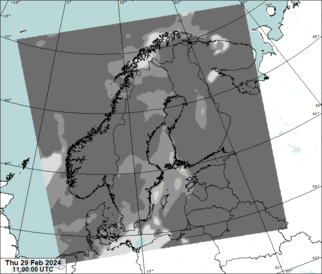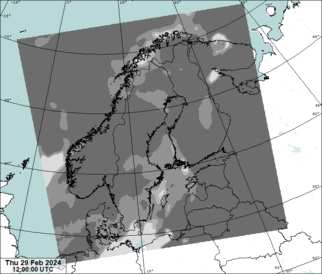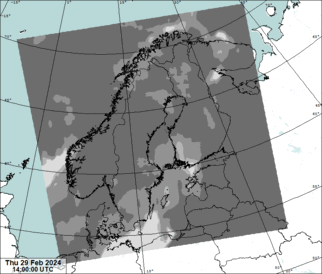
Source data for predictions is NWCSAF effective cloudiness:
This data is produced with 15-minute intervals. The model takes as input four previous satellite images (=1 hour), and can produce forecast of any length. In practice the quality of the predictions is not that good after three hours. In FMI we predict up to five hours, as the last two prediction hours are used to blend the forecast with NWP forecast.
In addition to the four previous times we also include sun elevation angle and leadtime (a running number 0,1,....) as predictors.
The geographical domain is that of MEPS (MEPS25D): northern europe in lambert conformal conic projection, 2.5 km grid. The satellite coverage is very poor in the north-east corner of the domain which can be seen as a visible saw blade-shaped static artifact.
The NWCSAF effective cloudiness has known issues which we try to correct before the data is fed to the neural network to make a prediction. Our training data set does not have this correction.
- Cumulus clouds are reported as 100% cloud cover, probably due to the resolution of the data. We try to fix this by using short range radiation information to decrease the cloud cover
- Shallow low level clouds are sometimes not detected during autumn/winter. We have different methods to try to fix this big quality issue
- Unnatural "clear sky" areas if there are clouds on different levels, probably due to shadow effect. We have methods to try to fix this too.
These corrections are made with Himan tool. Training data does not have these corrections.
Additionally in spring and autumn sometime at the sun flares hitting satellite sensor causes the cloudiness to increase to nearly 100% for the whole domain for some timesteps, usually at late evening.
The model is written with tensorflow2. Training resolution is 512x512 pixels, meaning ~5km resolution. In operations we downscale the output data to 2.5km. The network has ~31 million trainable parameters.
Training data contained 3 years of NWCSAF data in 15-minute intervals. Loss function is binary crossentropy combined with L1 loss.
Training was done with Nvidia V100 32G and it took ~2 days. Training was done with mixed precision (f16/f32).
Input and output data format is grib.
Based on our internal verification, cloudcast beats any NWP cloud cover forecasts in the three hour prediction window.
In order to run the model yourself, you need
- the code itself
- model weights
- source data
Code is found at this repo, but it is easier to use a pre-built container image (that's what we use too):
https://quay.io/repository/fmi/cloudcast
Both cpu and gpu versions are included, tags latest and latest-cuda.
The current best model weights are downloadable from here:
Size is around 325MB.
Build a container that has the weights inside.
Containerfile:
FROM quay.io/fmi/cloudcast:latest
ADD https://lake.fmi.fi/cc_archive/models/unet-bcl1-hist=4-dt=False-topo=False-terrain=False-lc=12-oh=False-sun=True-img_size=512x512.tar.gz .
RUN cat *.tar.gz | tar zxvf - -i && rm -f *.tar.gz
Build it:
podman build -t cloudcast-oper .
Test files are located at:
https://lake.fmi.fi/cc_archive/test_data/nwcsaf/2024/01/15/20240115T120000_nwcsaf_effective-cloudiness.grib2
https://lake.fmi.fi/cc_archive/test_data/nwcsaf/2024/01/15/20240115T114500_nwcsaf_effective-cloudiness.grib2
https://lake.fmi.fi/cc_archive/test_data/nwcsaf/2024/01/15/20240115T113000_nwcsaf_effective-cloudiness.grib2
https://lake.fmi.fi/cc_archive/test_data/nwcsaf/2024/01/15/20240115T111500_nwcsaf_effective-cloudiness.grib2
These files contain the fixes mentioned earlier. Cloudcast reads the data from a pre-defined directory structure. Filenames also need to be in specific format (as seen above).
Output of the network (the prediction) can be written either directly to s3, or to local directory. This is selected with option --directory.
If using s3, make sure env variables S3_ACCESS_KEY_ID, S3_SECRET_ACCESS_KEY and S3_HOSTNAME are set.
If using local write, mount a volume from host to container.
In this example local directory is used:
podman run --rm \
-e CLOUDCAST_INPUT_DIR=https://lake.fmi.fi/cc_archive/test_data \
-e PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python \
-e TF_CPP_MIN_LOG_LEVEL=3 \
-v $HOME/tmp:/mnt/output:z \
-it cloudcast-oper \
python3.9 infer.py --label unet-bcl1-hist=4-dt=False-topo=False-terrain=False-lc=12-oh=False-sun=True-img_size=512x512 \
--directory /mnt/output \
--analysis_time "2024-01-15 12:00:00" \
--output_size 1069x949 \
--prediction_len 20 \
--merge_gribs
/usr/local/lib/python3.9/site-packages/gribapi/__init__.py:23: UserWarning: ecCodes 2.31.0 or higher is recommended. You are running version 2.27.1
warnings.warn(
Loading models/unet-bcl1-hist=4-dt=False-topo=False-terrain=False-lc=12-oh=False-sun=True-img_size=512x512
WARNING:tensorflow:Mixed precision compatibility check (mixed_float16): WARNING
The dtype policy mixed_float16 may run slowly because this machine does not have a GPU. Only Nvidia GPUs with compute capability of at least 7.0 run quickly with mixed_float16.
If you will use compatible GPU(s) not attached to this host, e.g. by running a multi-worker model, you can ignore this warning. This message will only be logged once
Placeholder timeseries length: 4 number of samples: 20
Generator number of batches: 20 batch size: 1
Reading https://lake.fmi.fi/cc_archive/test_data/nwcsaf/2024/01/15/20240115T111500_nwcsaf_effective-cloudiness.grib2
Reading https://lake.fmi.fi/cc_archive/test_data/nwcsaf/2024/01/15/20240115T113000_nwcsaf_effective-cloudiness.grib2
Reading https://lake.fmi.fi/cc_archive/test_data/nwcsaf/2024/01/15/20240115T114500_nwcsaf_effective-cloudiness.grib2
Reading https://lake.fmi.fi/cc_archive/test_data/nwcsaf/2024/01/15/20240115T120000_nwcsaf_effective-cloudiness.grib2
Using ['20240115T111500', '20240115T113000', '20240115T114500', '20240115T120000'] to predict 20240115T121500
1/1 [==============================] - 7s 7s/step
Using ['20240115T111500', '20240115T113000', '20240115T114500', '20240115T120000'] to predict 20240115T123000
1/1 [==============================] - 6s 6s/step
Using ['20240115T111500', '20240115T113000', '20240115T114500', '20240115T120000'] to predict 20240115T124500
1/1 [==============================] - 6s 6s/step
Using ['20240115T111500', '20240115T113000', '20240115T114500', '20240115T120000'] to predict 20240115T130000
[..]
Wrote file /mnt/output/20240115120000.grib2
- analysis_time: the newest data that's available from the satellite, cloudcast will automatically read this and 3 previous times
- prediction_len 20: make a forecast of 5 hours (4*5 steps)
- merge_gribs: result is just one file with all grib messages inside
Model can be run with or without gpu; without gpu it takes ~6-8 seconds to make a single step prediction.
$ grib_ls $HOME/tmp/20240115120000.grib2
/home/partio/tmp/20240115120000.grib2
edition centre date dataType gridType stepRange typeOfLevel level shortName packingType
2 efkl 20240115 af lambert 0 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 15 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 30 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 45 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 1 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 75 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 90 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 105 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 2 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 135 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 150 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 165 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 3 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 195 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 210 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 225 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 4 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 255 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 270 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 285 heightAboveGround 0 unknown grid_ccsds
2 efkl 20240115 af lambert 5 heightAboveGround 0 unknown grid_ccsds
21 of 21 messages in /home/partio/tmp/20240115120000.grib2
21 of 21 total messages in 1 files
Training data is located at s3://cc_archive/nwcsaf. Following the NWCSAF data license this is not available to general public.
Reading grib from s3 is too slow for training, therefore numpy file(s) should be created. This can be done with script create-dataset.py. Script creates npy files which can be read through linux memory mapping technique, which means that the whole data does not need to read to memory. Upcoming changes will switch to using zarr for data handling.
For training we have used data from NWCSAF versions v2016 and v2018.
Once the source data is created, script cloudcast-unet.py is used to start training. The current model version is trained with:
python3 cloudcast-unet.py \
--loss_function bcl1 \
--n_channels 4 \
--leadtime_conditioning 12 \
--preprocess img_size=512x512 \
--dataseries_directory /path/to/data/dir \
--include_sun_elevation_angle
If you'd like to create your own training dataset for some other geographical domain than Northern Europe, you need access to NWCSAF data.
NWCSAF provides output in netcdf which need to be converted to grib2, and then preferrably to numpy. You can also skip grib and create numpy from netcdf files directly.
- First geotag the netcdf files and write the output as geotiff
gdal_translate -of GTiff -a_srs '+proj=geos +ellps=GRS80 +lon_0=0.000000 +h=35785863.000000 +sweep=y' -a_ullr -5570249.202 5438231.202 5567248.202 2653856.798 NETCDF:S_NWC_CTTH_MSG3_MSG-N-VISIR_20240101T040000Z_PLAX.nc:ctth_effectiv geotag.tif
- Crop to wanted domain and convert to grib
gdalwarp -t_srs '+proj=lcc +lat_0=63.3 +lon_0=15 +lat_1=63.3 +lat_2=63.3 +units=m +no_defs +ellps=WGS84 +datum=WGS84' -r bilinear -wo SOURCE_EXTRA=100 geotag.tif geotag2.tif
gdalwarp -te -1064963.311 -1340554.308 1318611.801 1341951.017 geotag2.tif geotag3.grib2
- Fix grib metadata which is not correctly set by gdal tools
grib_set -s dataDate=20240101,dataTime=400,... geotag3.grib2 20240101T040000.grib2
- For efficient training, create a numpy archive from these files with script create-dataset.py
For better performance the gdal-based commands can also be implemented for example with gdal python bindings.
Ideas, comments, bug reports through github issues or email (located at my profile page).