This project investigates "role-conditioning" behavior across multiple model families (Mistral 7B, Qwen 2.5 7B, and Llama 3.1 8B) using mechanistic interpretability to identify how models process self-referent vs. neutral vs. third person vs. confounder (implied 2nd person) content. The current form of this analysis focuses on attention entropy patterns and identifies candidate heads and layers that may be involved in role-conditioning behavior. I also develop simple heuristic measurements that can hopefully indicate ongoing role compliance on a simple dataset. There are early indications that the Role Focus Coefficient (RFC) might be a good candidate for approximating role-oriented-behavior in instruction-tuned models, though the effects differ across model families.
The initial evidence indicates that a native multi-lingual LLM, like Qwen, maintains higher focus on self-reference queries, providing early evidence that there may be a specific self-referent circuit. This treatment is unlike English-centric models. Mistral and Llama have different overall changes in self-referent entropy from base to instruct models. However both models have a post-training entropy profile where self-referent entropy is similar to neutral prompt entropy, and distinctly different from third-person or "confounder"/implied second-person queries.
Cross-Model RFC Analysis Results [See Metrics]
- Llama 3.1 8B: Mean -0.0233 (68.8% layers show compression, 15.6% near zero)
- Mistral 7B: Mean -0.0934 (81.2% layers show compression, 6.2% near zero)
- Qwen 2.5 7B: Mean +0.0475 (21.4% layers show preservation, 50% near zero)
- English models (Llama, Mistral): Show compression patterns (68.8% and 81.2% of layers respectively)
- Multilingual model (Qwen): Shows preservation in some layers (21.4%) but most layers are unchanged (50% near zero)
- Correlation: Llama vs Mistral show moderate positive correlation (r=0.398, p=0.024)
Qwen's multilingual training appears to maintain self-reference circuits largely unchanged after instruction tuning (50% of layers near zero), while English-native models show systematic compression of self-reference processing toward fact-finding (neutral) circuits. This suggests Qwen treats self-reference as a linguistically distinct circuit that instruction tuning doesn't significantly modify.
Role-specific linguistic circuits modulate attention patterns when input context implies identity or task roles. This circuit mapping provides insights into how language models internally represent and condition on speaker/subject identity markers.
Current Findings Indications that instruction tuned models neatly separate role-based queries from self-referential ones. Early evidence that Mistral tracks self-reference into similar circuits as "fact-finding" neutral questions, while Qwen maintains a distinct circuit for self-reference. This is potentially useful for the development of "dashboard-style" compliance metrics which can be rapidly calculated on relevant sample data. RFC appears to be a reasonable candidate for such a metric, given a controlled dataset of self-referent, neutral, third-, and confounding prompts.
├── requirements.txt # Python dependencies
├── prompts.py # Test prompts (self-referent, confounders, neutral, third-person)
├── experiment.py # Basic text generation experiment
├── activation_analysis.py # Advanced activation analysis with hooks
├── interventions.py # Intervention experiments with ablations
├── visualize_results.py # Comprehensive visualization suite
├── compare_base_instruct.py # Base vs instruct model comparison
├── cross_model_correlation.py # Cross-model RFC correlation analysis
├── activation_patching_analysis.py # Robust activation patching candidate identification
├── analyze_results.py # Results analysis and CSV export
├── output_manager.py # Output file management
├── deterministic.py # Deterministic setup utilities
├── targeted_interventions.json # Intervention configuration
├── model_family_config.json # Configuration for all model families
├── run_pipeline.py # Automated pipeline script
├── visualization_config.json # Model architecture configurations
├── figures/ # Organized visualization outputs
│ ├── llama/ # Llama 3.1 8B results
│ │ ├── base/ # Base model visualizations
│ │ ├── instruct/ # Instruct model visualizations
│ │ └── comparison/ # Base vs Instruct comparison
│ ├── qwen/ # Qwen 2.5 7B results
│ │ ├── base/
│ │ ├── instruct/
│ │ └── comparison/
│ └── mistral/ # Mistral 7B results
│ ├── base/
│ ├── instruct/
│ └── comparison/
├── results_activation_analysis/ # Mistral analysis results and raw data
├── results_llama_activation/ # Llama analysis results and raw data
├── results_qwen_activation/ # Qwen analysis results and raw data
├── activation_patching_results_robust/ # Robust activation patching analysis results
└── README.md # This file
1. Setup Environment:
python -m venv venv && source venv/bin/activate
pip install -r requirements.txt2. Run Complete Analysis Pipeline (Recommended):
# Run full pipeline for any model family (analysis + visualization + comparison)
python run_pipeline.py --family llama
python run_pipeline.py --family qwen
python run_pipeline.py --family mistral
# With custom parameters
python run_pipeline.py --family llama --prompts_per_category 20 --device cpu
# Skip analysis if data already exists
python run_pipeline.py --family llama --skip_analysis3. Run Individual Components:
# Run activation analysis for specific model
python activation_analysis.py --model_id meta-llama/Llama-3.1-8B --prompts_per_category 20 --output_type latest_base --output_dir results_llama_activation
# Generate visualizations using family config
python visualize_results.py --family llama --variant base
# Compare base vs instruct models
python compare_base_instruct.py --family llama
# Run cross-model correlation analysis
python cross_model_correlation.py
# Run robust activation patching analysis
python activation_patching_analysis.py --model_family llama --top_k 104. Legacy Individual Scripts:
# Run with 30 prompts per category on instruct model
python activation_analysis.py --prompts_per_category 30
# Generate visualizations for specific model
python visualize_results.py --output_type normal --input_dir results_activation_analysis/latest_run --model_name mistralai/Mistral-7B-Instruct-v0.1
# Run intervention experiments
python interventions.py --prompts_per_category 30This creates organized visualizations in the figures/{family}/{variant}/ directory structure.
The project now uses a centralized configuration system for easy multi-model analysis:
{
"model_families": {
"llama": {
"base": {
"model_id": "meta-llama/Llama-3.1-8B",
"output_type": "base",
"output_dir": "results_llama_activation",
"figures_dir": "figures/llama/base"
},
"instruct": {
"model_id": "meta-llama/Llama-3.1-8B-Instruct",
"output_type": "normal",
"output_dir": "results_llama_activation",
"figures_dir": "figures/llama/instruct"
},
"comparison": {
"base_dir": "results_llama_activation/latest_base",
"instruct_dir": "results_llama_activation/latest_run",
"output_dir": "figures/llama/comparison"
}
}
},
"defaults": {
"device": "cpu",
"prompts_per_category": 20,
"seed": 123
}
}The pipeline script automates the entire workflow:
- Activation Analysis - Extract activations from base and instruct models
- Visualization - Generate all 9 visualization plots
- Comparison - Compare base vs instruct models
# Run complete pipeline for any model family
python run_pipeline.py --family llama
python run_pipeline.py --family qwen
python run_pipeline.py --family mistral
# Customize parameters
python run_pipeline.py --family llama --prompts_per_category 30 --device cpu
# Skip steps if data already exists
python run_pipeline.py --family llama --skip_analysis
python run_pipeline.py --family llama --skip_visualization
python run_pipeline.py --family llama --skip_comparisonThe cross_model_correlation.py script performs statistical analysis across model families to identify patterns in how instruction tuning affects role-conditioning circuits.
- Loads RFC difference data from all model families (Llama, Mistral, Qwen)
- Calculates summary statistics for each model's RFC changes
- Performs correlation analysis between English models (Llama vs Mistral)
- Identifies directional patterns across model families
- Saves results to
cross_model_analysis_results.json
- English models (Llama, Mistral): Show negative RFC changes → instruction tuning compresses self-reference
- Multilingual model (Qwen): Shows positive RFC changes → instruction tuning preserves self-reference
- Correlation: Llama vs Mistral show moderate positive correlation (r=0.35, p=0.049)
python cross_model_correlation.pyThis analysis reveals that Qwen's multilingual training maintains self-reference as a linguistically distinct circuit even after instruction tuning, while English-native models shift self-reference processing toward fact-finding (neutral) circuits.
The activation_patching_analysis.py script implements a robust methodology to identify specific attention heads that are candidates for activation patching experiments. This analysis uses advanced statistical methods to isolate role-specific effects and avoid false positives.
Statistics:
- Median aggregation across prompts
- Log-ratios with data-scaled epsilon
- Difference-in-Differences (DiD) to isolate role-specific effects:
(H_self_instruct - H_self_base) - (H_neutral_instruct - H_neutral_base)
Guardrails Against False Positives:
- Consistency scoring: Fraction of prompts with same direction
- Baseline focus: Prioritizes heads with low baseline entropy (specialized)
- Composite scoring: Balances magnitude, consistency, and baseline focus
Top Activation Patching Candidates (Robust Methodology):
Llama 3.1 8B:
- Layer 5, Head 8: DiD -0.0103 ↓, Log-Ratio -0.320, Consistency 0.93
- Layer 16, Head 23: DiD -0.0039 ↓, Log-Ratio -0.313, Consistency 0.83
- Layer 14, Head 3: DiD 0.0895 ↑, Log-Ratio 0.286, Consistency 0.97
Mistral 7B:
- Layer 27, Head 5: DiD -0.0616 ↓, Log-Ratio -1.028, Consistency 0.77
- Layer 9, Head 26: DiD 0.0562 ↑, Log-Ratio 0.647, Consistency 0.83
- Layer 15, Head 16: DiD 0.1084 ↑, Log-Ratio 0.581, Consistency 0.90
# Run robust activation patching analysis
python activation_patching_analysis.py --model_family llama --top_k 10
python activation_patching_analysis.py --model_family mistral --top_k 10This analysis provides a much more reliable foundation for activation patching experiments, with clear role-specific effects and defensible statistical measures.
- Tested on: MacBook Pro M4 (48GB RAM)
- Expected runtime: ~10-15 minutes per model for activation analysis (30 prompts/category)
- Memory: ~16GB RAM needed for Mistral-7B model loading
- Storage: ~6GB per analysis run
Direct questions about the model's identity and capabilities:
- "Who created you?"
- "What are you?"
- "Describe yourself."
- "What is your purpose?"
- "How do you work?"
- "Are you conscious?"
- "Do you have feelings?"
- "What are your capabilities?"
- "What are your limits?"
- "Can you think?"
- etc.
First-person perspective but not about the model itself:
- "How tall am I?"
- "What should I eat?"
- "Where do I live?"
- "When is my birthday?"
- "What language do I speak?"
- "How old am I?"
- "What color are my eyes?"
- "Where was I born?"
- "What is my name?"
- "Do I have siblings?"
- etc.
No first-person perspective:
- "What is photosynthesis?"
- "How do planes fly?"
- "What causes rain?"
- "Explain gravity."
- "What is DNA?"
- "How does the internet work?"
- "What are black holes?"
- "Describe the water cycle."
- "What is democracy?"
- "How do vaccines work?"
- etc.
Third-person perspective for control comparison:
- "How tall is she?"
- "What should he eat?"
- "Where does she live?"
- "When is his birthday?"
- "What language does she speak?"
- "How old is he?"
- "What color are her eyes?"
- "Where was he born?"
- "What is her name?"
- "Does he have siblings?"
- etc.
- Deterministic generation run_with_cache() forward only, 0 temp no sampling
- Hook-based activation capture for all 32 layers
- Attention pattern extraction with entropy calculations
- Raw data export to NPZ files for detailed analysis
- Targeted ablation of specific attention heads
- Graded interventions (0.5 and 0.0 ablation methods)
- Structured output organization by intervention type and parameters
- Raw intervention data saved for comparison with baseline runs
- Layer-wise attention patterns with 95% confidence intervals
- Head-wise Δ-heatmaps (Self - Neutral, Self - Confounder)
- Token-conditioned attention patterns across key layers
- Distribution plots with Cohen's d effect sizes
- Δ-bar summary per layer (Confounder - Self, Neutral - Self)
- Top-K head ranking per layer (most role-sensitive heads)
- Cross-token control analysis (first 3 vs last 3 tokens)
- ΔH per layer analysis (Confounder - Self entropy difference)
- Role-Focus & Separation indices (RFC & RSI with confidence intervals)
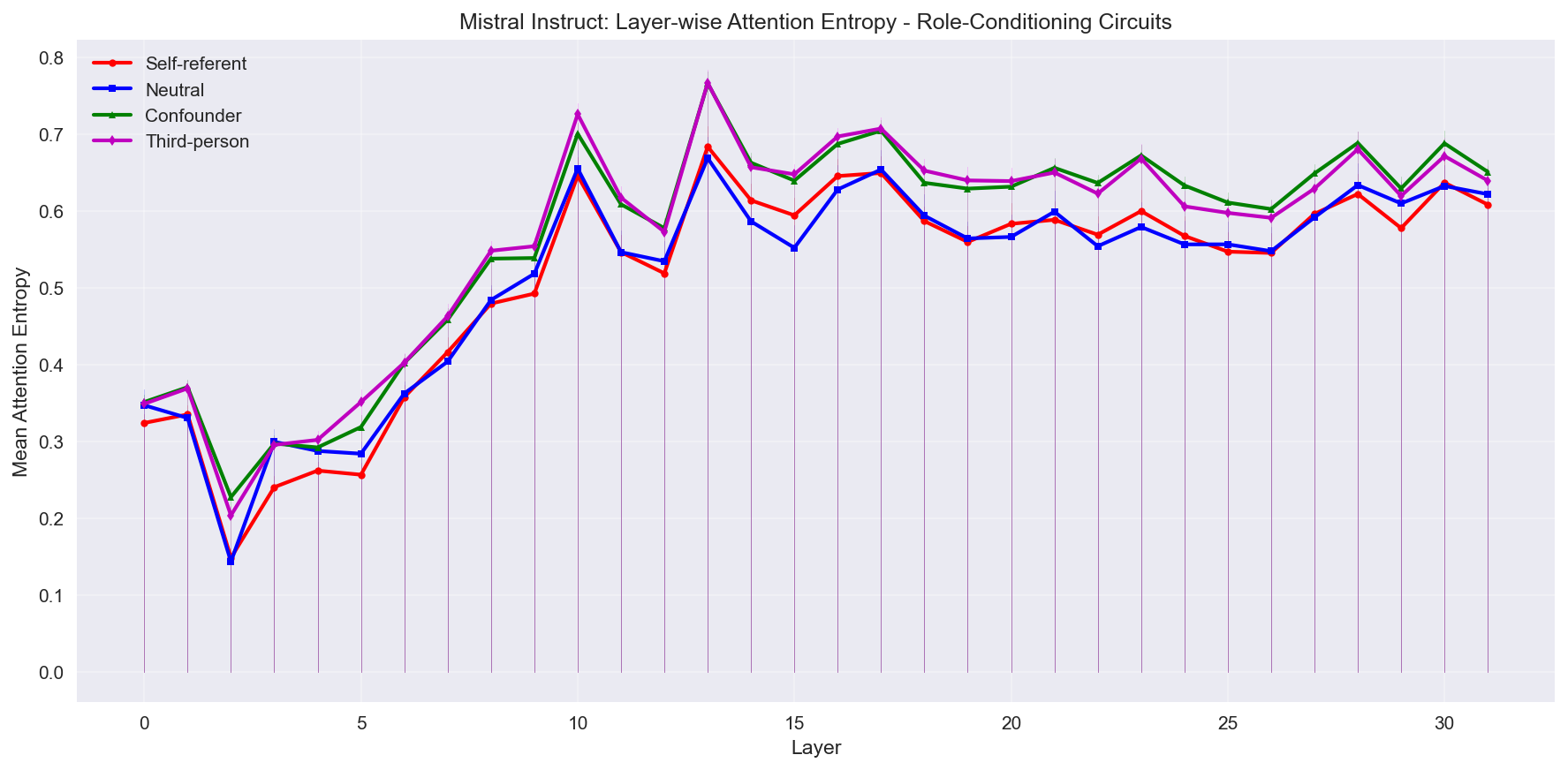 Shows attention entropy progression across all 32 layers with 95% confidence intervals. Self-referent prompts (red) and neutral (blue) consistently show lower entropy (more focused attention) compared to confounder (green) prompts and third person (magenta) prompts.
Shows attention entropy progression across all 32 layers with 95% confidence intervals. Self-referent prompts (red) and neutral (blue) consistently show lower entropy (more focused attention) compared to confounder (green) prompts and third person (magenta) prompts.
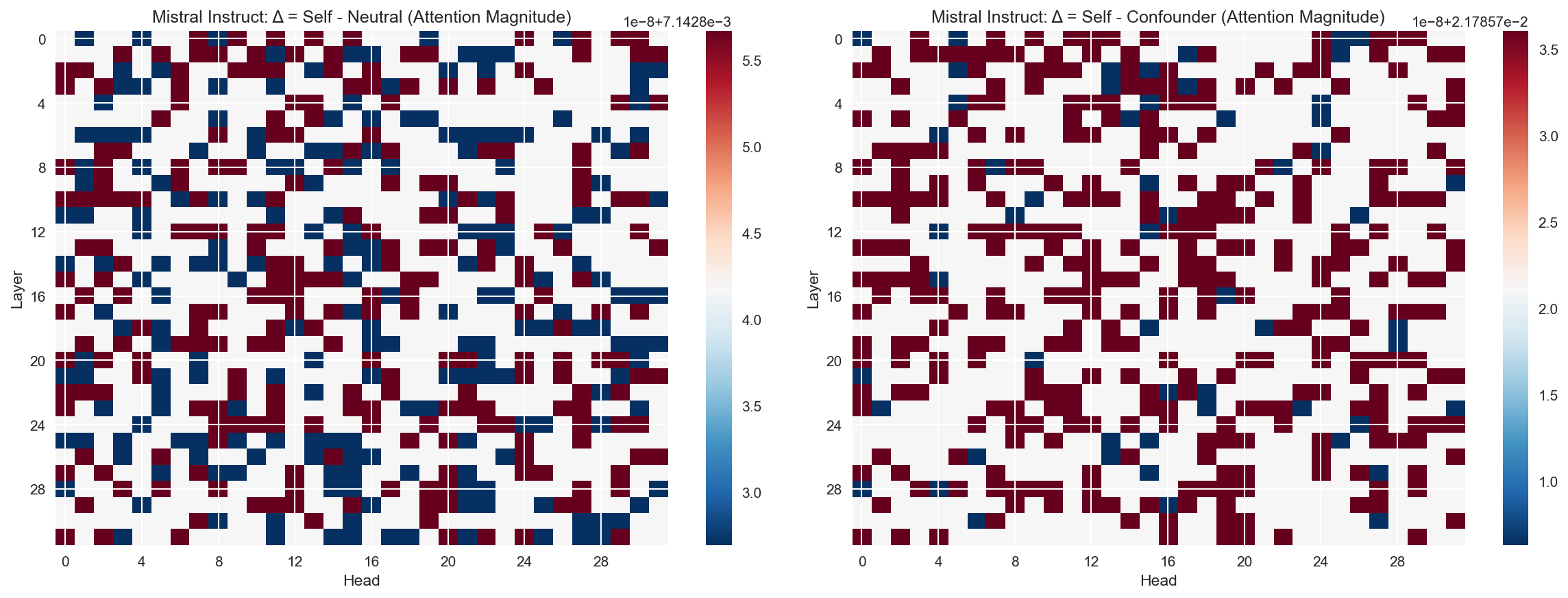 Identifies specific attention heads that are most sensitive to role-conditioning. Red regions indicate heads where self-referent prompts show different attention patterns compared to neutral/confounder prompts.
Identifies specific attention heads that are most sensitive to role-conditioning. Red regions indicate heads where self-referent prompts show different attention patterns compared to neutral/confounder prompts.
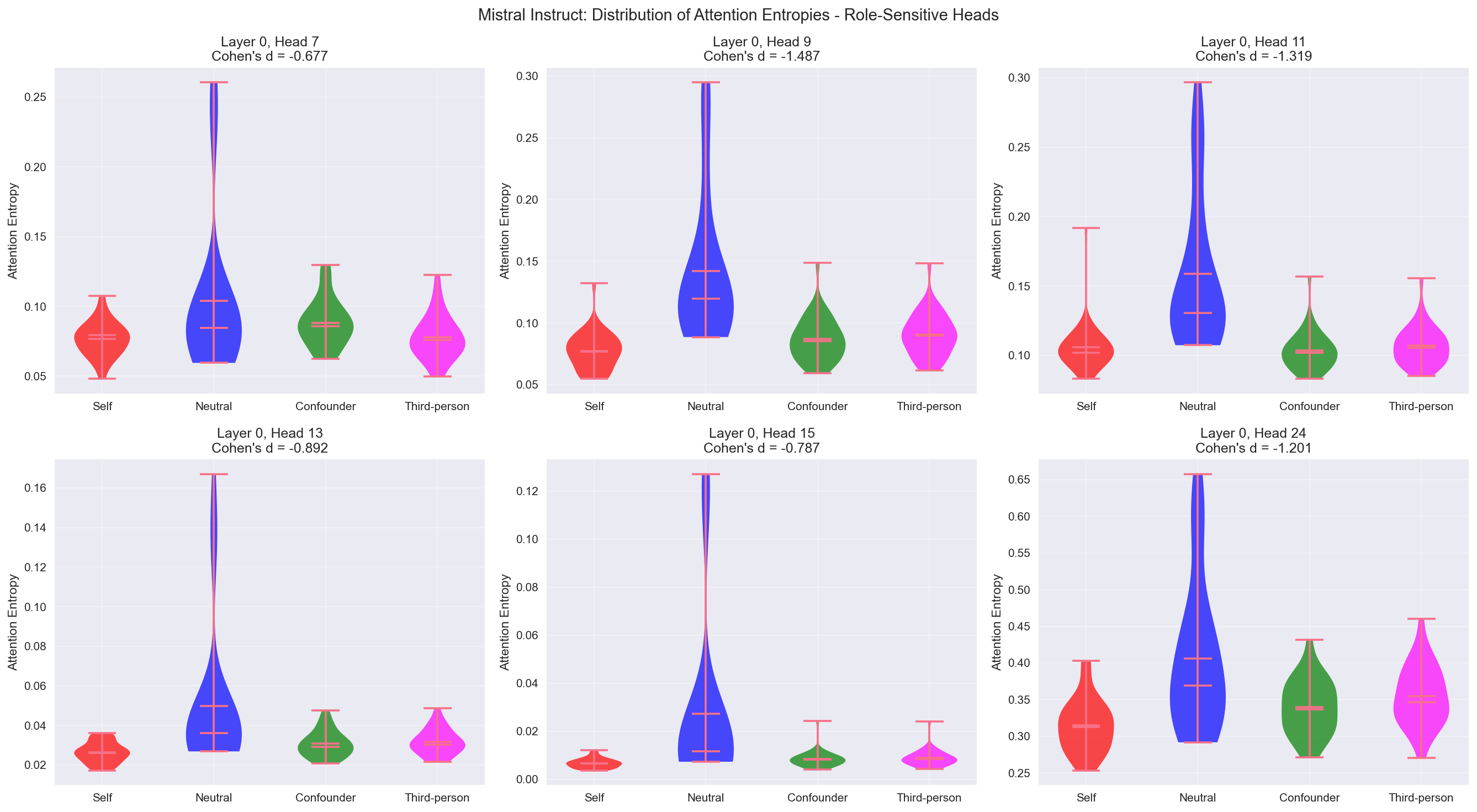 Violin plots showing attention entropy distributions for the most role-sensitive heads across all four categories. Large negative Cohen's d values indicate self-referent prompts produce more focused attention patterns compared to confounder and third-person prompts. But at these particular heads, neutral is most diffuse. Indicates these heads might be "role-orientation" nodes.
Violin plots showing attention entropy distributions for the most role-sensitive heads across all four categories. Large negative Cohen's d values indicate self-referent prompts produce more focused attention patterns compared to confounder and third-person prompts. But at these particular heads, neutral is most diffuse. Indicates these heads might be "role-orientation" nodes.
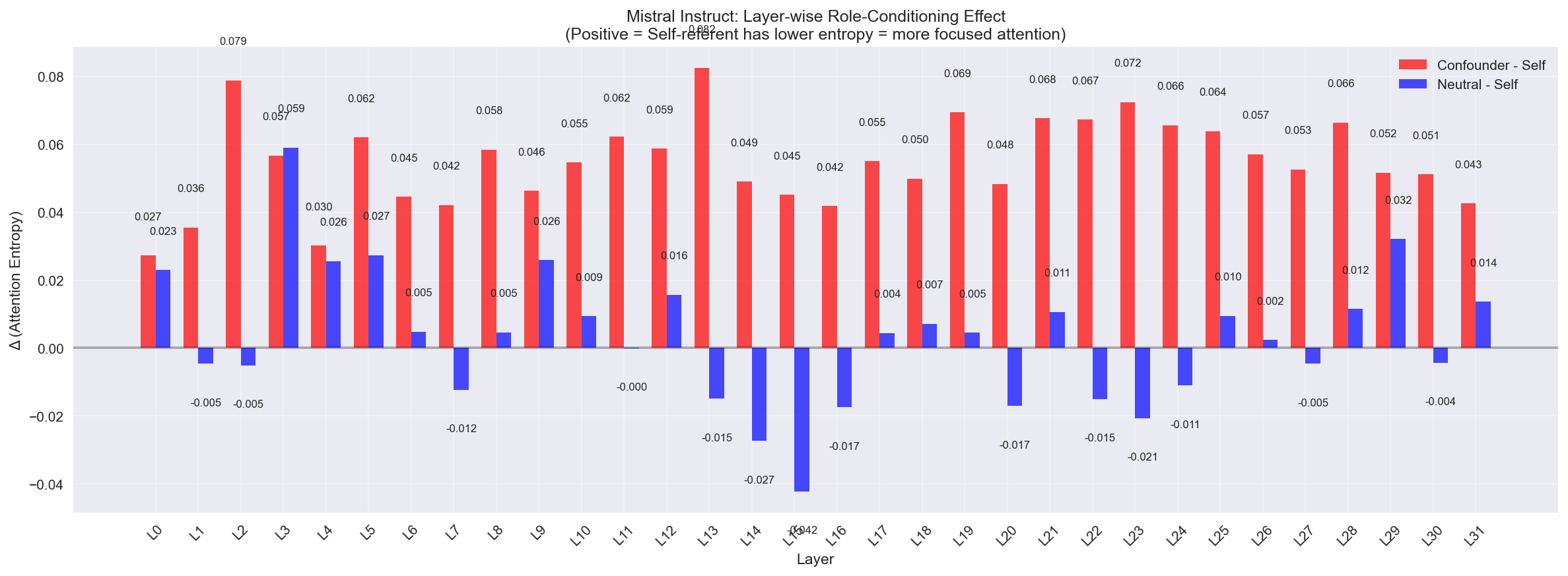 Quantitative summary showing layer-wise differences between conditions. Positive values indicate self-referent prompts have more focused attention (lower entropy) than confounder/neutral prompts.
Quantitative summary showing layer-wise differences between conditions. Positive values indicate self-referent prompts have more focused attention (lower entropy) than confounder/neutral prompts.
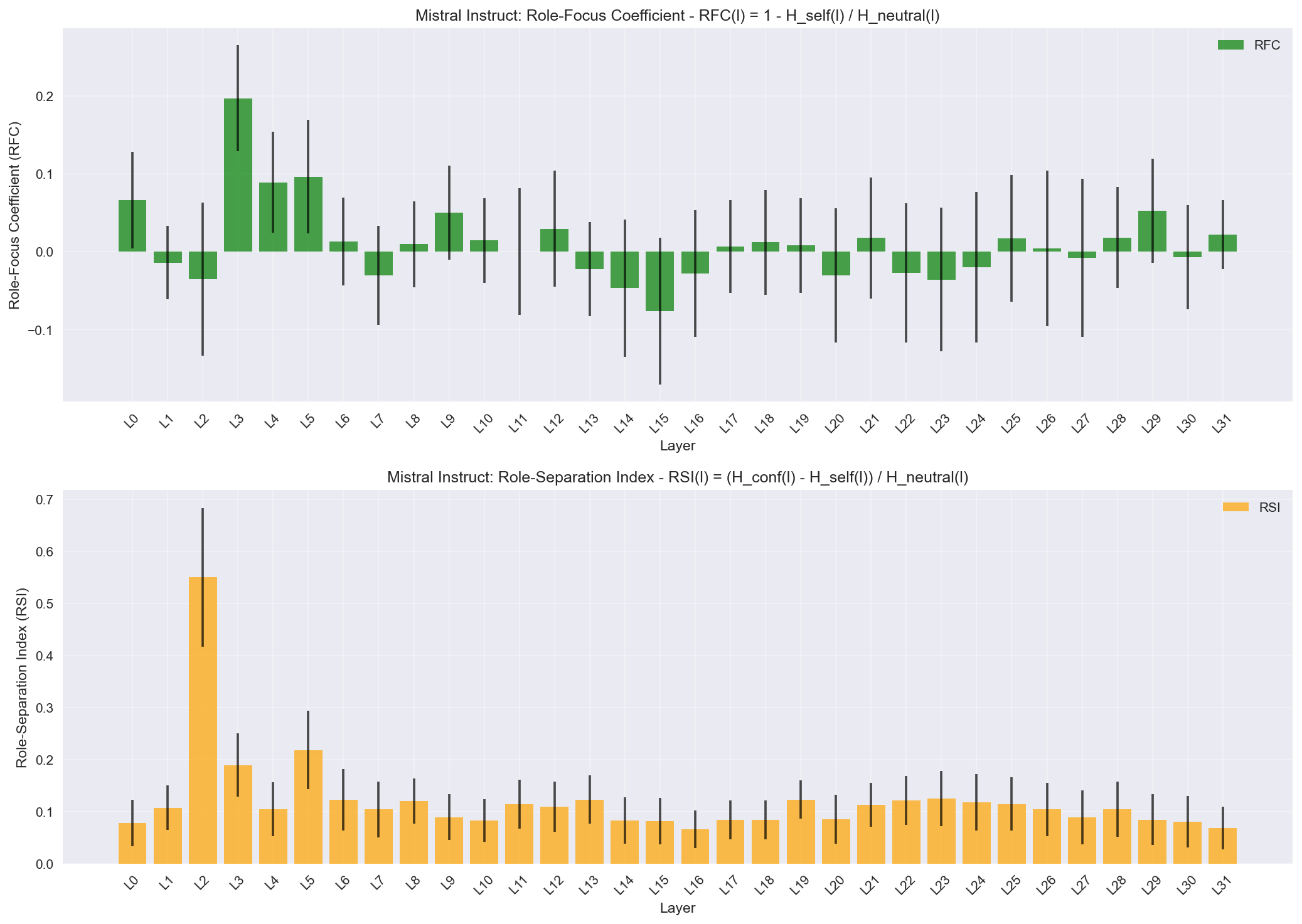 Proposed RFC and RSI metrics with confidence intervals. RFC measures how much more focused self-referent attention is compared to neutral, while RSI measures the separation between confounder and self-referent patterns.
Proposed RFC and RSI metrics with confidence intervals. RFC measures how much more focused self-referent attention is compared to neutral, while RSI measures the separation between confounder and self-referent patterns.
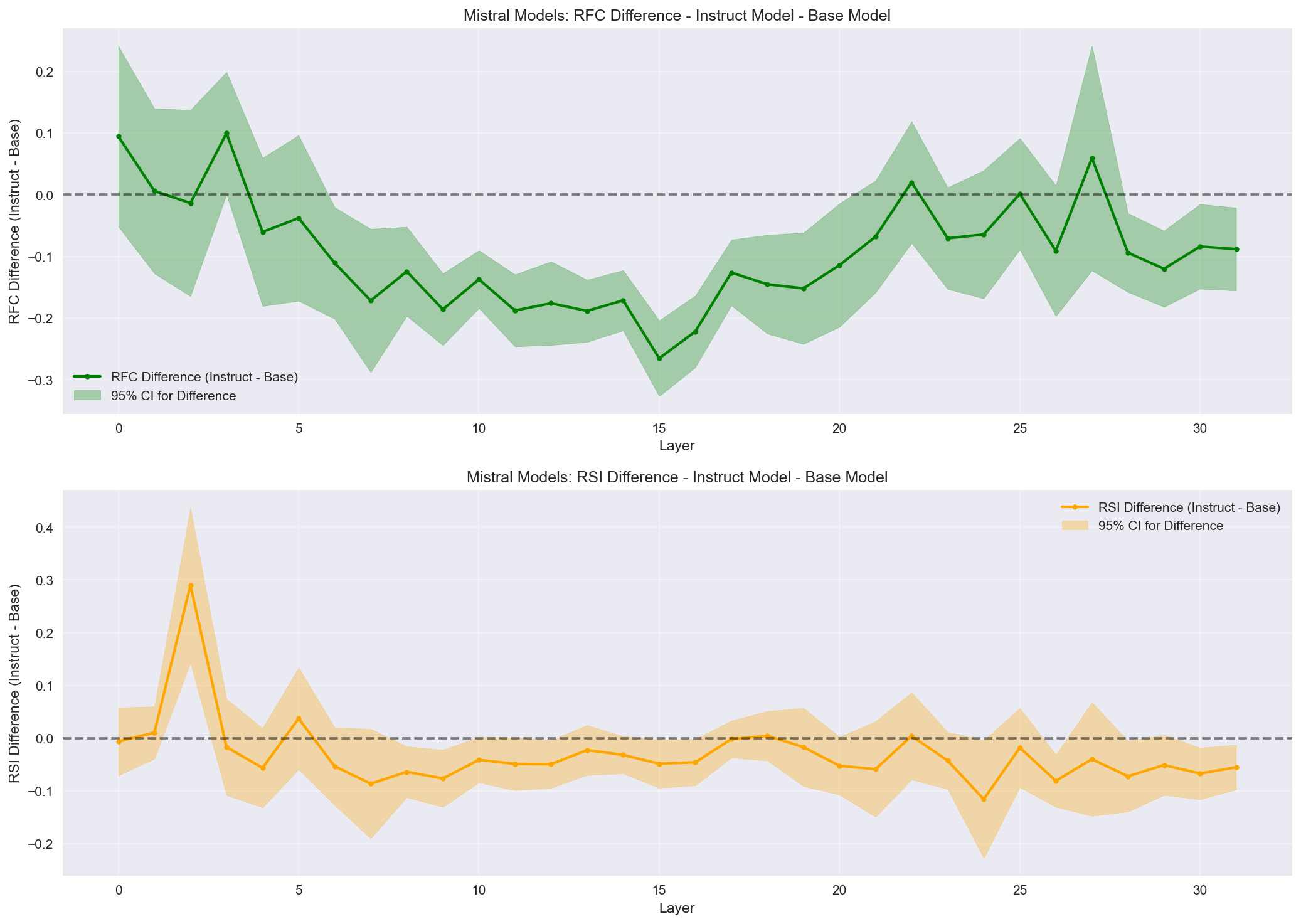 Statistical comparison of RFC and RSI differences between base and instruct models with 95% confidence intervals. RFC in base model middle layers is >> 0, whereas instruct models ~= 0, showing much more focused attention on self-reference in base vs instruct models. A potentially useful dashboard metric for fine-tuning effectiveness, tracking the alignment of fact-based treatment with self-oriented prompts.
Statistical comparison of RFC and RSI differences between base and instruct models with 95% confidence intervals. RFC in base model middle layers is >> 0, whereas instruct models ~= 0, showing much more focused attention on self-reference in base vs instruct models. A potentially useful dashboard metric for fine-tuning effectiveness, tracking the alignment of fact-based treatment with self-oriented prompts.
- Attention Entropy: Measures focus vs. distributed attention
- Role-Focus Coefficient (RFC):
RFC(l) = 1 - H_self(l) / H_neutral(l) - Role-Separation Index (RSI):
RSI(l) = (H_conf(l) - H_self(l)) / H_neutral(l) - Effect Sizes: Cohen's d for within-head statistical significance
Run activation analysis:
python activation_analysis.py --help # See all options
python activation_analysis.py --prompts_per_category 30 --device cpuGenerate visualizations:
python visualize_results.py # Creates all 9 plots in figures/Run basic experiment:
python experiment.py --model_id mistralai/Mistral-7B-Instruct-v0.1 --prompts_per_category 5figures/ # Organized by model family and variant
├── llama/ # Llama 3.1 8B results
│ ├── base/ # Base model visualizations
│ │ ├── visualization_1_layer_attention_lines.png
│ │ ├── visualization_2_heatmaps.png
│ │ ├── visualization_3_token_attention.png
│ │ ├── visualization_4_distributions.png
│ │ ├── visualization_5_delta_bar_summary.png
│ │ ├── visualization_6_top_k_head_ranking.png
│ │ ├── visualization_7_cross_token_control.png
│ │ ├── visualization_8_delta_h_per_layer.png
│ │ └── visualization_9_role_focus_separation.png
│ ├── instruct/ # Instruct model visualizations
│ │ └── [same 9 visualizations]
│ └── comparison/ # Base vs Instruct comparison
│ ├── rfc_rsi_comparison.png
│ ├── rfc_rsi_differences.png
│ └── detailed_comparison.csv
├── qwen/ # Qwen 2.5 7B results
│ ├── base/
│ ├── instruct/
│ └── comparison/
└── mistral/ # Mistral 7B results
├── base/
├── instruct/
└── comparison/
results_llama_activation/ # Llama analysis results
├── latest_base/ # Base model results
│ ├── activations.json # Processed activation data
│ ├── raw_*.npz # Raw activation arrays
│ └── experiment_config.json # Analysis configuration
└── latest_run/ # Instruct model results
├── activations.json
├── raw_*.npz
└── experiment_config.json
results_qwen_activation/ # Qwen analysis results
├── latest_base/
└── latest_run/
results_activation_analysis/ # Mistral analysis results (legacy)
├── latest_base/
├── latest_run/
└── latest_intervention/ # Intervention results
├── sh_29_26_zero_out/ # Layer 29, Head 26, zero ablation
├── sh_29_26_half_out/ # Layer 29, Head 26, half ablation
└── sh_11_2_zero_out/ # Layer 11, Head 2, zero ablation
model_family_config.json # Centralized configuration for all model families
├── model_families/
│ ├── llama/ # Llama configuration
│ ├── qwen/ # Qwen configuration
│ └── mistral/ # Mistral configuration
└── defaults/ # Default parameters
visualization_config.json # Model architecture configurations
├── models/ # Model-specific layer/head counts
└── default_model/ # Default model for visualization
The analysis typically reveals:
- RFC For Mistral, Base ≫ 0, Instruct ≈ 0 → instruction tuning removes self-reference as a distinct attention regime (role compression). Qwen shows Base >> 0 and Insruct >> 0, with only small early head differences.
- RSI Small, early positive bump in instruct → emergence of early-layer user/assistant separation.
- Interpretation In Mistral, instruction tuning re-orients self-referent processing into the factual-retrieval circuit. In Qwen, role separation is preserved between Base and Instruct.
Some early hypotheses about
- Layer-wise progression of role-conditioning effects
- Specific attention heads that are highly sensitive to role-oriented content
- Entropy differences indicating more focused attention for self-referent prompts compared to other "speakers"
- Statistical significance indicative, with large effect sizes (Cohen's d > 1.0)
- Token-position specificity showing effects are strongest for middle layer and late layer tokens
- Third-person control indicates speaker effects may be self-reference specific
- Python 3.12
- PyTorch 2.8.0
- TransformerLens 2.16.1
- Transformers 4.57.1
- NumPy, Pandas, Matplotlib, Seaborn
- SciPy (for statistical analysis)
- Activation Patching Candidates Identified:
- Llama: Layer 5 Head 8, Layer 16 Head 23, Layer 14 Head 3 (top candidates)
- Mistral: Layer 27 Head 5, Layer 9 Head 26, Layer 15 Head 16 (top candidates)
- Methodology: Robust DiD analysis with composite scoring (magnitude + consistency + baseline focus)
- Activation Patching Experiments ready to start with identified candidates
I hope this framework can be extended to:
- Intervention studies (activation patching)
- Scaling studies (7B → 70B → 405B parameter models)
- Task-specific analysis (reasoning, planning, tool use)
- Safety research (alignment, goal-seeking behavior)
- Deterministic by default (temperature=0, do_sample=False)
- Reproducible with seed control and deterministic setup
- Extensible for additional prompt categories and analysis types