Open
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Case-study оптимизации проекта
На одном проекте решил оптимизировать тесты. Написаны они на rspec, всего - 271 example, среднее время прогона 39 сек.
Построение feedback-loop
Исходное время прогона позволяет работать со всем suite целиком, к тому же rspec --profile не выявил особо "жирные" участки, которые можно было бы взять за основу
Поиск точек роста
Решил начать с проверки фабрик, но к сожалению (или к счатью) результаты были такими, что оптимизация в данном направлении не имела смысла
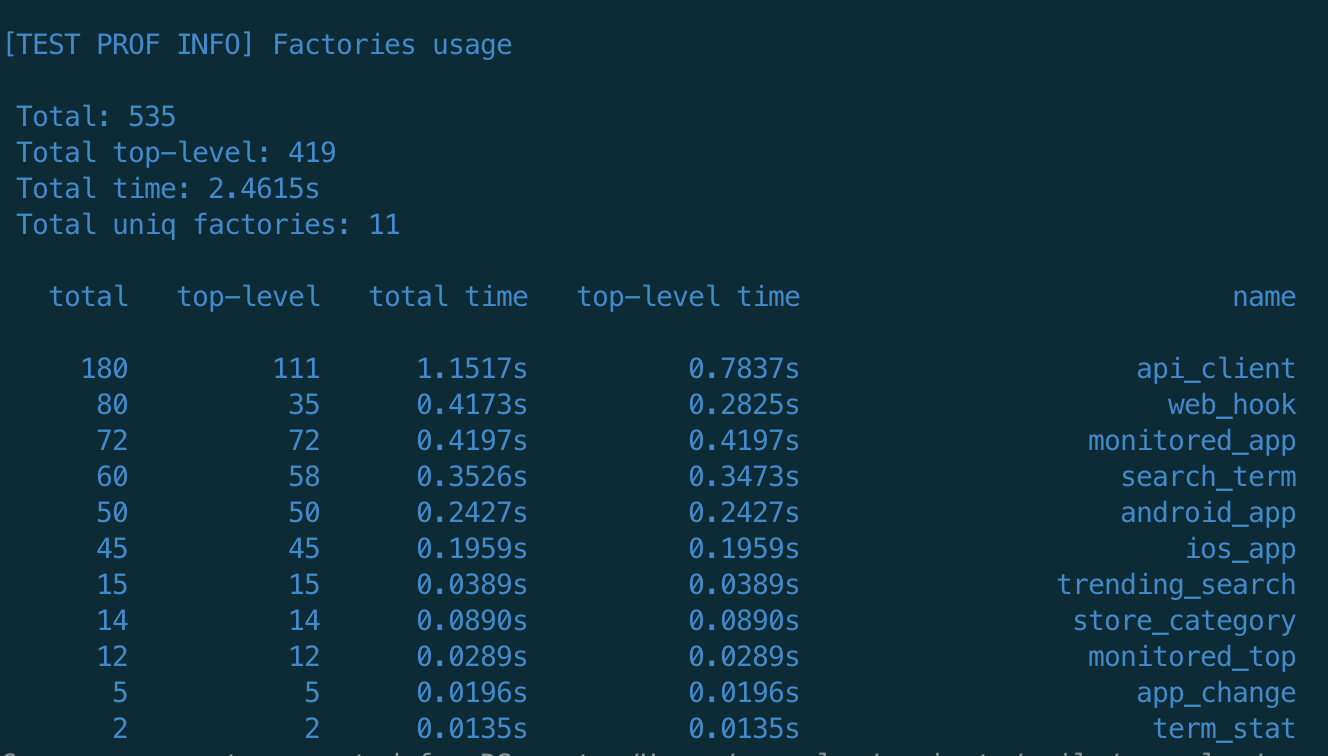
FactoryProf показала что всего на фабрики уходит 2, 46 сек причем явная проблема factory cascade отсутствовала
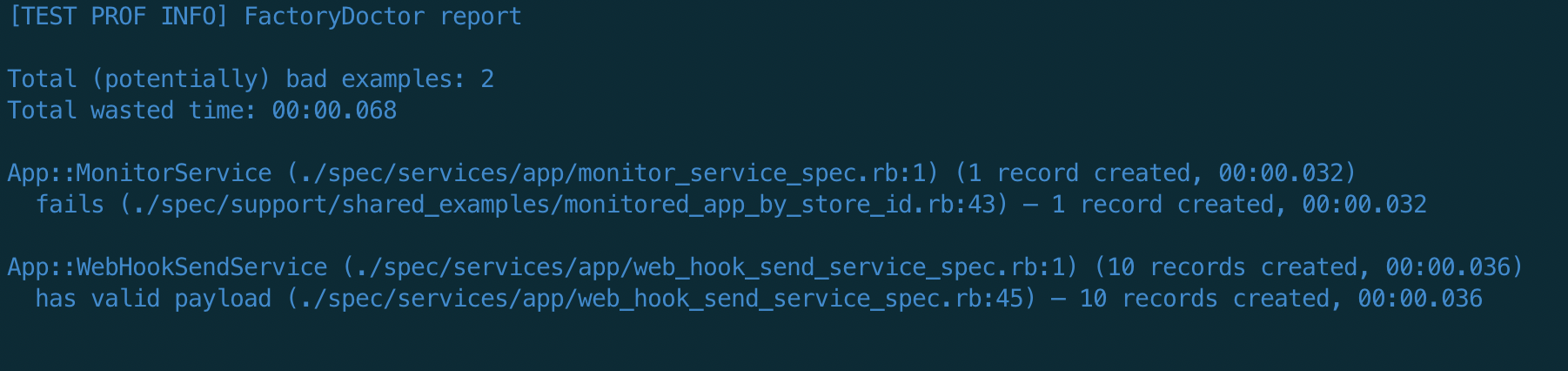
FactoryDoctor нашел 2 потенциальных места оптимизации с приросто 00:00.68 сек, т.е вообще не имеет смысла
Профилировщики общего характера показали, что основное процессорное время уходит на 2 библиотеки: Psych, которая парсит yaml и Nokogiri, которая парсит html
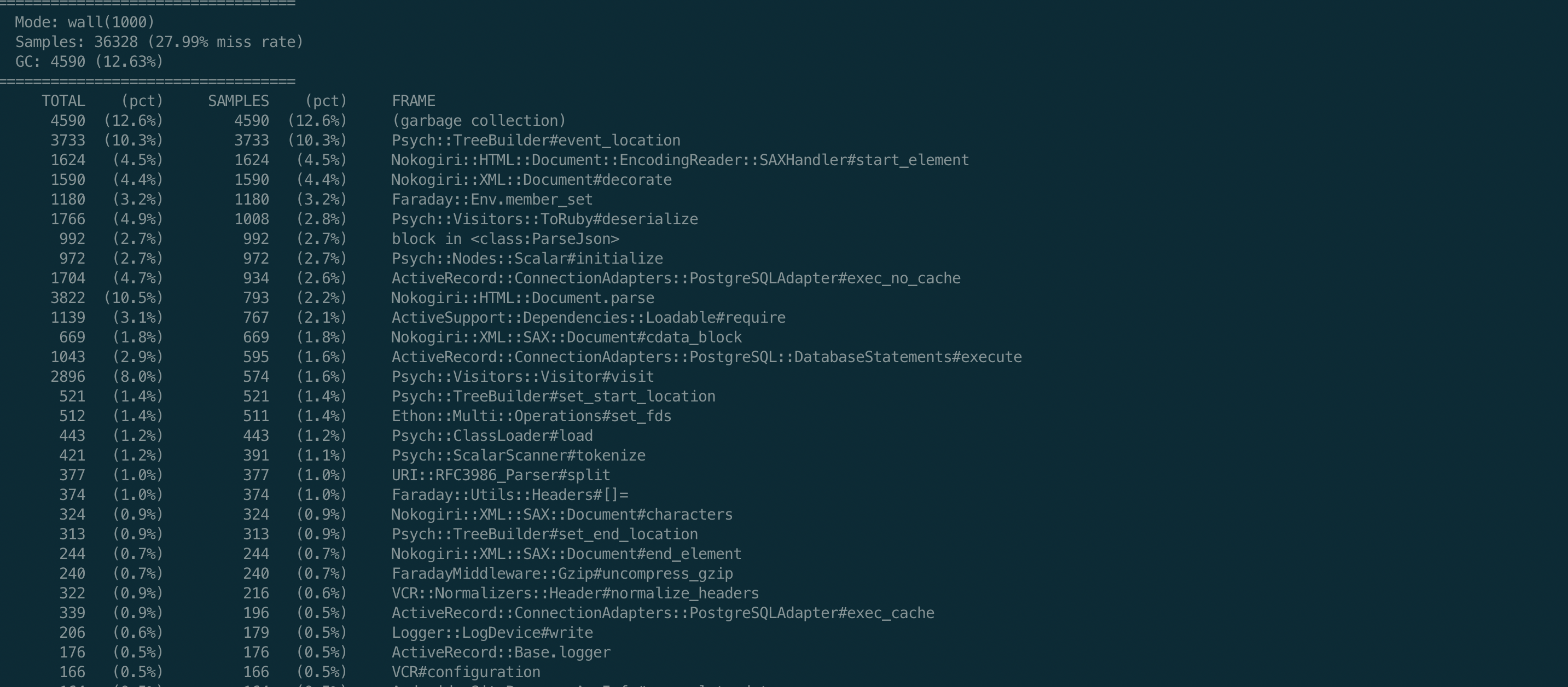
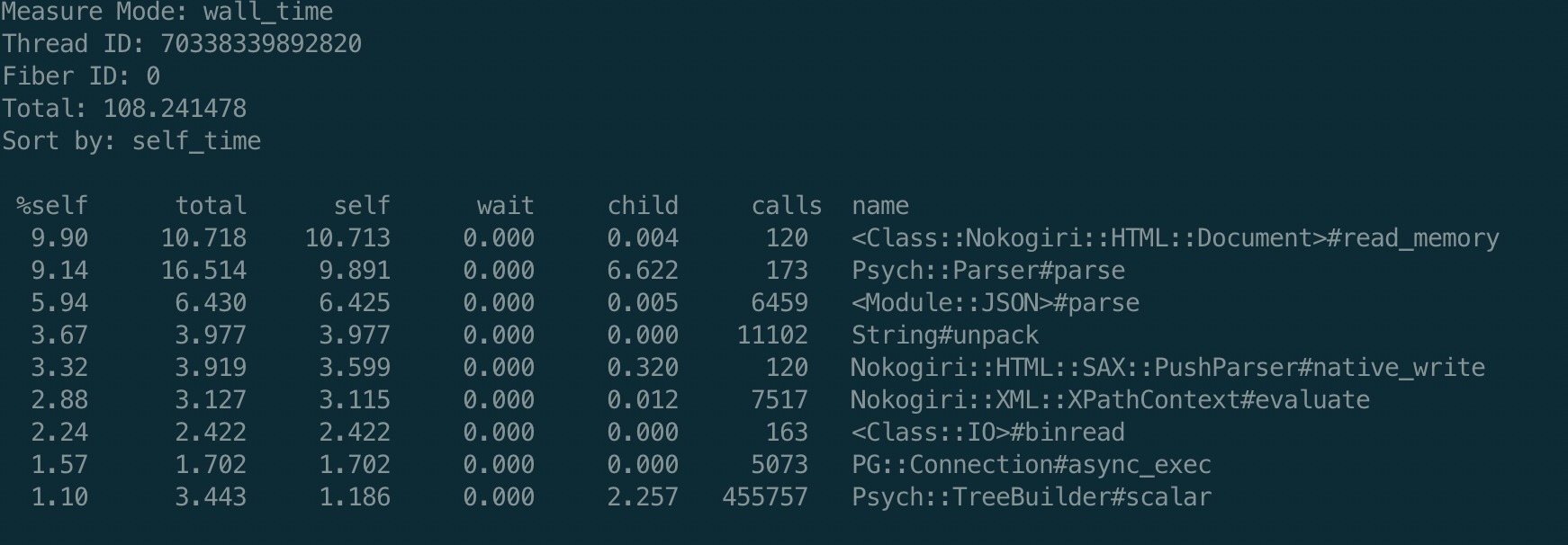
Я это связываю с тем, что в данном проекте в тестах очень активно используется гем VCR, который записывает сетевые HTTP взаимодействия и сериализует их в yaml для повторного воспроизведения (к тому же размер некоторых кассет достигает 70Мб, что явно не добавляет скорости)
К сожалению для того, чтобы выкинуть этот гем потребуется переписать большую част тестов, что естественно довольно затруднительно, поэтому какой прирост это дало бы сказать сложно.
Реальный прирост дало использование гема parallel_tests.
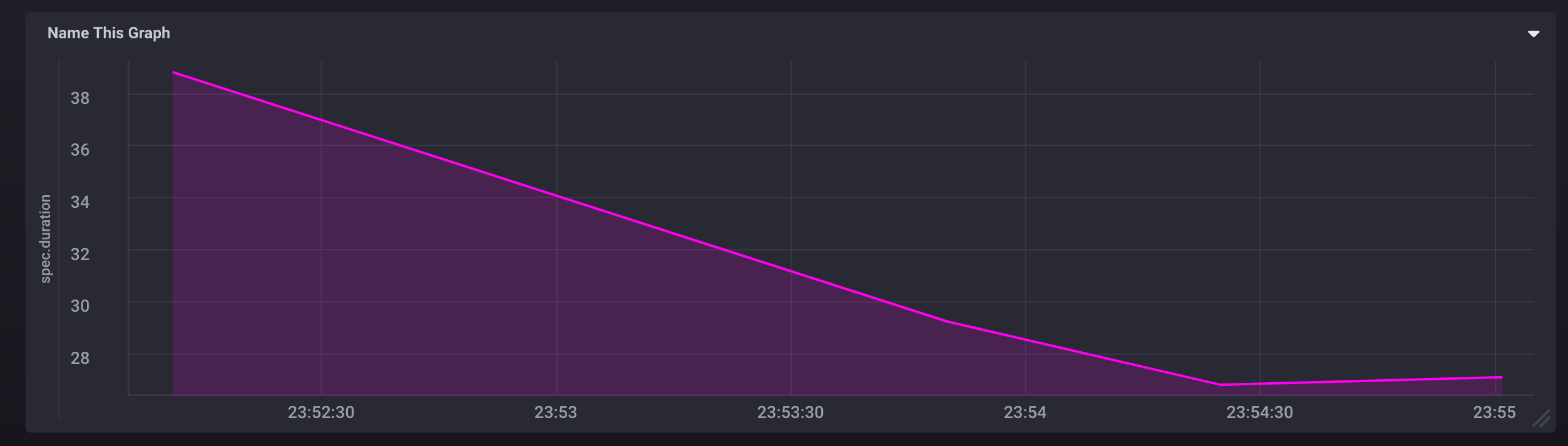
Время прогона сократилось с 39 до 26, что уже неплохо